Java Collection
- All kinds Maps implementation
- java.util.HashTable
- java.util.HashMap
- java.util.LinkedHashMap
- java.util.TreeMap
- java.util.IdentityHashMap
- java.util.EnumMap
- java.util.WeakHashMap
- Collections.synchronizedMap(aMap)
- java.util.concurrent.ConcurrentHashMap
- java.util.concurret.ConcurrentSkipListMap
All kinds Maps implementation
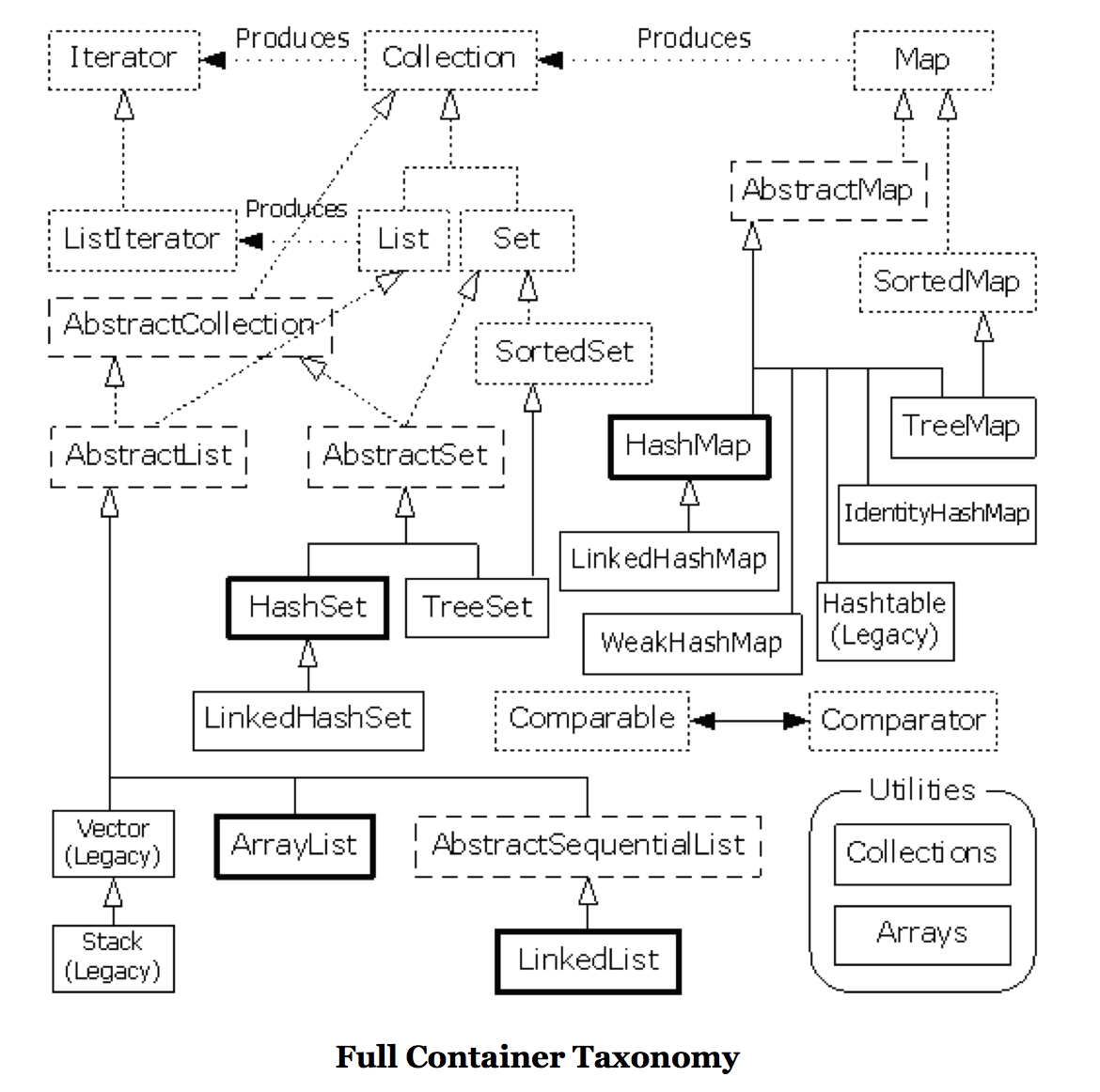
java.util.HashTable
- Legacy associative array implementation; Inducted to collection family by implementing Map interface later;
- All methods are “thread-safe”;
- there is “synchronozed” keyword on each public method such as(put,get,remove etc).
- overhead in an environment where Map is initialized once and the read by multiple threads.
java.util.HashMap
- Map implementation that satisfies most of the basic use cases.
- Not “thread-safe”.
- Iteration not guaranteed in insertion order.
- Need to use “synchronized” operations when manipulating from mutiple threads(concurrent adds/removes/iterations)
- Most enterprise applications populate the map once and then read many times from many threads. Given this HashMap suffices for all such scenarios, without any worries of performance overheads.
package collection;
/**
* Map的特点是一个键值对(key->value),其中key是唯一的,key和value都是对象
* put(key,value)往map中添加一个键值对,
* map.entrySet()把键和值作为一个Set中的一个元素
*
* Hashtable和HashMap的比较:
* Hashtable:JDK1.2之前的,底层实现的数据结构是hash表,是线程安全的(也就是同步的),key和value是不可以使用null
* 的,否则会抛出空指针异常的,效率是比较低的,一般我们不用它
* HashMap:JDK1.2之后的,底层实现的数据结构是hash表,是线程不安全的(也就是没有使用同步),key和value是可以为空的
* 效率是比较高的,在引用中建议大家使用它,
*/
import java.util.*;
import java.util.Map.Entry;
public class TableMap {
public static void main(String[] args) {
Hashtable<String, String> ht = new Hashtable<String, String>();
ht.put("sadfa", "werwerwer");
ht.put("34534", "werwefasf");
ht.put("99999", "988666565");
//ht.put(null, null);
//ht.put("8888", null);
System.out.println(ht.size());
Enumeration<String> keys = ht.keys();
while (keys.hasMoreElements()) {
String key = keys.nextElement();
System.out.println("key=" + key + " ,value" + ht.get(key));
}
Enumeration<String> values = ht.elements();
while (values.hasMoreElements()) {
String value = values.nextElement();
System.out.println("value=" + value);
}
System.out.println("--------------------------");
Map<String, String> map = new HashMap<String, String>();
map.put("001", "wangwu");
map.put("001", "lisi");
map.put("009", "sdafasdf");
map.put("003", "asdfsdfsdf");
Set<Map.Entry<String, String>> set = map.entrySet();
Iterator<Map.Entry<String, String>> it = set.iterator();
while (it.hasNext()) {
Entry<String, String> key_value = it.next();
System.out.println("key=" + key_value.getKey() + " ,value=" + key_value.getValue());
}
}
}
/*output:
3
key=sadfa ,valuewerwerwer
key=34534 ,valuewerwefasf
key=99999 ,value988666565
value=werwerwer
value=werwefasf
value=988666565
--------------------------
key=001 ,value=lisi
key=003 ,value=asdfsdfsdf
key=009 ,value=sdafasdf */
Q: How does HashMap work in Java?
ITS A MAP IMPLEMENTATION
- A Map is an associative array data structure. “key 1”——>value, “key2”——>value, “key3”——>value so on.
- Hashing: transformation of a string of characters(Text) to a shorted fixed-length value that represents original string. A shorter value helps in indexing and faster searches.
- In Java every object has method
public int hashcode()that will return a hash value for given object. - use bitwise operation
Q: WHAT’S THE BIG DEAL IN JAVA 8?
- In java 8, when we have too many unequal keys which gives same hashcode(Index) - when the number of items in a hash bucket grows beyond certain threshold(TREEIFY_THRESHOLD = 8), content of the bucket switches from using a linked list of Entry objects to a balanced tree. This theoretically improves the worst-case performance from O(n) to O(log n);
- Balanced search tree, where left nodes have lesser weight(HashCode or Comparable result) for the keys involved.
- When HashMap reaches its threshold limit of 0.75 or 75% it re-size by creating a new array of double the previous size HashMap, and then start putting every old element into that new bucket array and this is called rehashing and it also applies hash function to find new bucket location.
java.util.LinkedHashMap
- Very similar to HashMap
- Iteration is guaranteed in insertion order
- Maintains separate doubly linked list of all entries that is kept in entry insertion order.
- Can be used in use-cases where hash map like behavior is needed at the same time order of insertion has to be preserved.
package collection;
import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Set;
/*
* LinkedHashMap是HashMap的子类
* 底层实现的结构是链表和hash表,添加的顺序和取出的顺序相同
* 线程不安全的(非同步的,效率是高的)
* 如果对map进行频繁的插入和删除操作的话可以使用LinkedHashMap
* key和value同样可以为空,也就是可以添加null,要注意和Hashtable区分
*/
public class LinkedHashMapDemo {
public static void main(String[] args) {
LinkedHashMap<String, String> lhm = new LinkedHashMap<String, String>();
lhm.put("092101", "zhjangsan");
lhm.put("092102", "zhjsdfsan");
lhm.put("092103", "zh345gsan");
lhm.put("092104", "zhja76876san");
lhm.put("092104", "zhja76876san");
lhm.put(null, null);
lhm.put(null, "dsfasdf");
lhm.put("sdfasf", null);
System.out.println(lhm.size());
Set<String> set = lhm.keySet();
Iterator<String> it = set.iterator();
while (it.hasNext()) {
String key = it.next();
String value = lhm.get(key);
System.out.println("key=" + key + " ,value=" + value);
}
}
}
/*output:
6
key=092101 ,value=zhjangsan
key=092102 ,value=zhjsdfsan
key=092103 ,value=zh345gsan
key=092104 ,value=zhja76876san
key=null ,value=dsfasdf
key=sdfasf ,value=null */
java.util.TreeMap
- Implementation of SortedMap and NavigableMap interfaces.
- Iteration is guaranteed in “natural sorted” order of keys.
- Either the keys should implement “Comparable” interface(If not exception will be thrown: ClassCastException); If not we need to provide an explicit Comparator in the constructor;
- Red-black tree based implementation. NavigableMap interface provides methods that can return closes match to the key(floorEntry()…)
package collection.treemap;
import java.util.*;
/**
* 自然排序:和TreeSet一样,要让我们的自定义类本身具有可比较性
* 也就是要让我们的自定义类实现Comparable接口,并实现compareTo()方法
*/
class Employee {
private String name;
private int salary;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getSalary() {
return salary;
}
public void setSalary(int salary) {
this.salary = salary;
}
public Employee(String name, int salary) {
super();
this.name = name;
this.salary = salary;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "姓名:" + this.name + " ,薪水:" + this.salary;
}
//方法一
/*public int compareTo(Employee u) {
if (this.getSalary() - u.getSalary() < 0) {
return 1;
}
if (this.getSalary() - u.getSalary() > 0) {
return -1;
}
return this.name.compareTo(u.name);
}*/
}
public class TreeMapDemo {
public static void main(String[] args) {
TreeMap<Employee, String> map = new TreeMap<Employee, String>(new Comparator<Employee>() {
public int compare(Employee o1, Employee o2) {
if (o1.getSalary() - o2.getSalary() > 0) {
return -1;
}
if (o1.getSalary() - o2.getSalary() < 0) {
return 1;
}
return o1.getName().compareTo(o2.getName());
}
});
map.put(new Employee("zhangsan", 6000), "员工一");
map.put(new Employee("zhangsan", 6000), "员工一");
map.put(new Employee("zhang12", 7000), "员工3");
map.put(new Employee("zhangs4", 2000), "员工4");
map.put(new Employee("zhang0", 1000), "员工5");
System.out.println("==========================");
Set<Map.Entry<Employee, String>> set = map.entrySet();
Iterator<Map.Entry<Employee, String>> it = set.iterator();
while (it.hasNext()) {
Map.Entry mapEntry = it.next();
System.out.println(mapEntry.getKey() + " " + mapEntry.getValue());
}
System.out.println("===========descendingMap()===============");
Map<Employee, String> map2 = map.descendingMap();
Set<Map.Entry<Employee, String>> set2 = map2.entrySet();
Iterator<Map.Entry<Employee, String>> it2 = set2.iterator();
while (it2.hasNext()) {
Map.Entry mapEntry = it2.next();
System.out.println(mapEntry.getKey() + " " + mapEntry.getValue());
}
System.out.println("========min==============");
Map.Entry<Employee, String> me = map.firstEntry();
System.out.println("min.key=" + me.getKey() + " ,min_value=" + me.getValue());
System.out.println("=======floor==============");
Map.Entry<Employee, String> me2 = map.floorEntry(new Employee("zhang12", 8000));
System.out.println("min.key=" + me.getKey() + " ,min_value=" + me.getValue());
}
}
/*output
==========================
姓名:zhang12 ,薪水:7000 员工3
姓名:zhangsan ,薪水:6000 员工一
姓名:zhangs4 ,薪水:2000 员工4
姓名:zhang0 ,薪水:1000 员工5
===========descendingMap()===============
姓名:zhang0 ,薪水:1000 员工5
姓名:zhangs4 ,薪水:2000 员工4
姓名:zhangsan ,薪水:6000 员工一
姓名:zhang12 ,薪水:7000 员工3
========min==============
min.key=姓名:zhang12 ,薪水:7000 ,min_value=员工3
=======floor==============
min.key=姓名:zhang12 ,薪水:7000 ,min_value=员工3 */
java.util.IdentityHashMap
- Uses identity to store and retrieve key values.
- Use reference equality; meaning r1==r2 rather than r1.equals(r2). For hashing, System.identityHashCode(givenKey) is invoked rather than givenKey.hashCode()
- Used in seiralization/deep copying or your key is “Class” object or interned strings - memory footprint comparatively smaller than a hashmap as there no Entry/Node created.
package collection;
import java.util.IdentityHashMap;
import java.util.Iterator;
import java.util.Set;
/*
* IdentityHashMap:
* 继承结构:java.lang.Object java.util.AbstractMap<K,V> java.util.IdentityHashMap<K,V>
* 底层结构是哈希表,比较键(和值)时使用引用相等性代替对象相等性。
* 换句话说,在 IdentityHashMap 中,当且仅当 (k1==k2) 时,才认为两个键k1和k2相等,
* 在正常Map实现(如 HashMap)中,当且仅当满足(k1==null ? k2==null : e1.equals(e2))时才认为两个键k1和k2相等。
* key是比较地址,只要是通过new方式来创建的key,即使他们的每个属性都相等,而且也复写了hashCode和equals方法,
* 该“相同的”key也是可以放到map中的,因为key他们比较的是地址
*/
class User {
private String name;
private int age;
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public int hashCode() {
return this.name.hashCode() ^ 123 + this.age * 34;
}
@Override
public boolean equals(Object obj) {
if (this == obj) return true;
if (!(obj instanceof User)) {
return false;
}
final User u = (User) obj;
if (u.getAge() == this.getAge() && u.getName().equals(this.getName())) {
return true;
}
return false;
}
@Override
public String toString() {
// TODO Auto-generated method stub
return "name=" + this.name + " ,age=" + this.age;
}
public User(String name, int age) {
super();
this.name = name;
this.age = age;
}
}
public class IdentityHashMapDemo {
public static void main(String[] args) {
IdentityHashMap<User, String> map = new IdentityHashMap<User, String>();
map.put(new User("zhangsan", 20), "asdfsdaf");
map.put(new User("zhangsan", 20), "wamgwu");
Set<User> set = map.keySet();
Iterator<User> it = set.iterator();
while (it.hasNext()) {
User key = it.next();
String value = map.get(key);
System.out.println(key + " " + value);
}
System.out.println("==============identityHashMap=====String=======");
IdentityHashMap<String, String> map2 = new IdentityHashMap<String, String>();
map2.put(new String("99999"), "000000");
map2.put(new String("99999"), "111111");
map2.put("99999", "333333");
map2.put("99999", "444444");
Set<String> set2 = map2.keySet();
for (Iterator<String> it2 = set2.iterator(); it2.hasNext(); ) {
String key = it2.next();
System.out.println("key=" + key + " value=" + map2.get(key));
}
}
}
/*output:
name=zhangsan ,age=20 wamgwu
name=zhangsan ,age=20 asdfsdaf
==============identityHashMap=====String=======
key=99999 value=111111
key=99999 value=000000
key=99999 value=444444 */
java.util.EnumMap
- EnumMap<K extends Enum
, V> - for use with enum type keys. All of the keys in an enum map must come from a single enum type that is specified, explicitly or implicitly, when the map is created.
- Null keys not permitted. Not synchronized.
- Iterator does not fail-fast —— if you create an enum map and add some enumeration key value pairs into the enum map and then iterate all the keys and then try to put something into the map in between it does not fail(throw ConcurrentModificationException) ConCurrentModificationException —— When trying to read from a certain list or a map, some other thread or this current thread(与多线程无关) itself is trying to modify that list or map, so in that kind of scenario this exception is thrown.
package scratch;
import java.util.HashMap;
import java.util.Iterator;
import java.util.Map;
public class ConcEx {
public static void main(String[] args) {
Map<String, Integer> scores = new HashMap<>();
scores.put("user1", 6);
scores.put("user2", 6);
scores.put("user3", 6);
scores.put("user4", 6);
scores.put("user5", 6);
scores.put("user6", 6);
scores.put("user7", 6);
scores.put("user8", 6);
Iterator<String> userItr = scores.keySet().iterator();
while(userItr.hasNext()){
System.out.println(scores.get(userItr.next()));
scores.put("user9", 6);
}
}
}

java.util.WeakHashMap
- Elements in a weak hashmap can be reclaimed by the garbage collector if there are no other strong references to the object, this makes them useful for caches/lookup storage.
- Keys inserted gets wrapped in java.lang.ref.WeakReference
- Useful only if the desired lifetime of cache entries is determined by external references to the key, not the value
- SoftHashMap??
package scratch;
import java.util.Map;
import java.util.WeakHashMap;
class Order {
int orderId;
String details;
public Order(int orderId, String details) {
this.orderId = orderId;
this.details = details;
}
}
public class WKHMap {
public static void main(String[] args) {
Map<Order, Integer> orders = new WeakHashMap<>();
// Weak References
orders.put(new Order(1, "fdfsfs"), 100);
orders.put(new Order(2, "asdfa"), 200);
// Strong References
Order o3 = new Order(3,"ggsggsg");
orders.put(o3, 300);
System.out.println(orders.size());
System.gc();
System.out.println(orders.size());
}
}
/*Output:
3
1 */
Collections.synchronizedMap(aMap)
- A convenient “decorator” to create fully synchronized map.
- Return type is Collections.SynchronizedMap instance. It wraps around passed map instance and marks all APIs as synchronized, effectively making it similar to HashTable
- Provide as a convenience as of 1.2 to users. Feel free not to use it.
java.util.concurrent.ConcurrentHashMap
- Supports full concurrency during retrieval. Means, retrieval operations do not block even if adds are during concurrently(mostly)
- Reads can happen fast, while writes require a lock. Write lock is acquired at granular level, whole table is not locked only segments are locked. So a very rare chance of read waiting on write to complete.
- By defalut the concurrent hash map is divided into sixteen segments and we can add sixteen threads to write into the hash map at the given time.
- Iterations do not throw concurrent modification exception(with in same thread).
- Can be used in cases where a lot of concurrent addition happens followed by concurrent reads later on.
- Null key not allowed. If map.get(null) returns null, it is not sure if null is not mapped or if null is mapped to a null value. In a non-concurrent map, we could use contains() call, but in a concurrent map, values can change between API calls.
- Operation not atomic.
package scratch;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
public class ConcHmapExample {
static Map<String, Long> orders = new ConcurrentHashMap<>();
static void processOrders() {
for (String city : orders.keySet()) {
for (int i = 0; i < 50; i++) {
Long oldOrder = orders.get(city);
orders.put(city, oldOrder+1);
}
}
}
public static void main(String[] args) {
orders.put("Bombay", 0l);
orders.put("Beijing", 0l);
orders.put("London", 0l);
orders.put("New York", 0l);
ExecutorService service = Executors.newFixedThreadPool(2);
service.submit(ConcHmapExample::processOrders);
service.submit(ConcHmapExample::processOrders);
try {
service.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
service.shutdown();
System.out.println(orders);
}
}
预计运行结果:

在多线程情况下,运行结果如下
在终端运行结果:
wyj Java Contanier
$ cd bin
wyj bin
$ while true
> do
> java scratch.ConcHmapExample
> done;
{Beijing=59, New York=55, Bombay=51, London=55}
{Beijing=61, New York=56, Bombay=57, London=77}
{Beijing=51, New York=50, Bombay=51, London=71}
{Beijing=54, New York=60, Bombay=84, London=90}
{Beijing=61, New York=49, Bombay=66, London=65}
{Beijing=50, New York=57, Bombay=55, London=96}
{Beijing=65, New York=53, Bombay=67, London=58}
{Beijing=70, New York=62, Bombay=61, London=80}
{Beijing=65, New York=68, Bombay=70, London=85}
{Beijing=57, New York=55, Bombay=56, London=55}
{Beijing=65, New York=70, Bombay=69, London=50}
{Beijing=72, New York=67, Bombay=76, London=100}
{Beijing=97, New York=79, Bombay=75, London=73}
{Beijing=54, New York=54, Bombay=69, London=66}
{Beijing=50, New York=58, Bombay=53, London=75}
{Beijing=82, New York=76, Bombay=96, London=100}
{Beijing=50, New York=67, Bombay=72, London=79}
{Beijing=61, New York=66, Bombay=70, London=100}
{Beijing=56, New York=55, Bombay=73, London=84}
{Beijing=65, New York=59, Bombay=66, London=82}
········
we get inconsistent output as 100. Reasons:
Long oldOrder = orders.get(city);
orders.put(city, oldOrder+1);
Operations above are not atomic.
Improvement method 1: synchcronize them; Method 2: Use atomic types —— writes chang before any other read happens in the memory.
package scratch;
import java.util.Map;
import java.util.concurrent.ConcurrentHashMap;
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;
import java.util.concurrent.TimeUnit;
import java.util.concurrent.atomic.AtomicLong;
public class ConcHmapExample {
static Map<String, AtomicLong> orders = new ConcurrentHashMap<>();
static void processOrders() {
for (String city : orders.keySet()) {
for (int i = 0; i < 50; i++) {
// atomic operation on the atomicLone.
orders.get(city).getAndIncrement();
}
}
}
public static void main(String[] args) {
orders.put("Bombay", new AtomicLong());
orders.put("Beijing", new AtomicLong());
orders.put("London", new AtomicLong());
orders.put("New York", new AtomicLong());
ExecutorService service = Executors.newFixedThreadPool(2);
service.submit(ConcHmapExample::processOrders);
service.submit(ConcHmapExample::processOrders);
try {
service.awaitTermination(1, TimeUnit.SECONDS);
} catch (InterruptedException e) {
e.printStackTrace();
}
service.shutdown();
System.out.println(orders);
}
}
运行结果:
wyj bin
$ while true
> do
> java scratch.ConcHmapExample
> done;
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
{Beijing=100, New York=100, Bombay=100, London=100}
........
java.util.concurret.ConcurrentSkipListMap
- An equivalent of TreeMap in the concurrent word.
- A scalable concurrent ConcurrentNavigableMap/SortedMap implementation.
- Gurantees average O(log(n)) performance on a wide variety of opearations. ConcurrentHashMap does not guarantee operation time as part of its contrast.